Chapter 3
1. Breadth-first search (BFS) tree
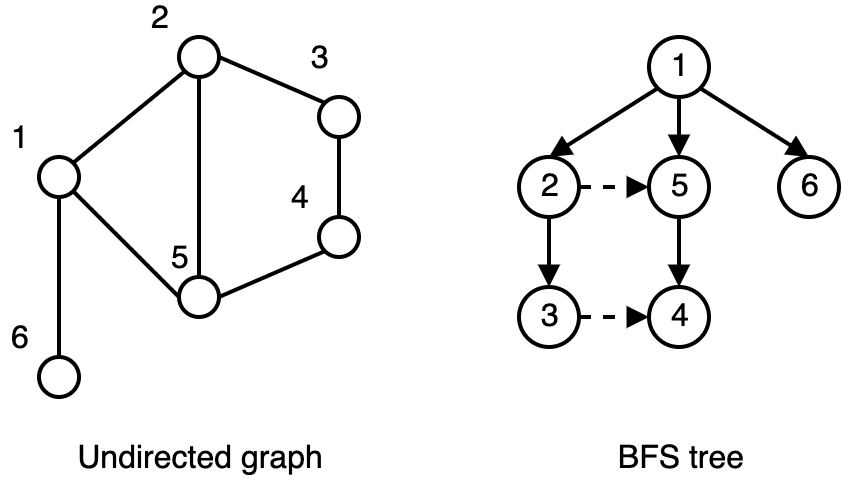
This is not a programming activity. Tracing the breadth-first search (BFS) algorithm for a problem results in a BFS tree. Here is an example BFS tree. Below is a map of India highlighting some of the international airports in the country. Nick wants to go to Amritsar from Chennai. In PAPER, draw a BFS tree for the graph of airport cities with starting node as Chennai (C).
{kind=link}
{kind=link}
- Lectures: Uninformed Search Algorithms

2. Implement the breadth-first search (BFS) algorithm
With the help of the code blocks provided below, implement the BFS algorithm (in Python) to find the shortest path from Sibiu to Bucharest in the following map. Note that in a standard BFS algorithm/implementation, we ignore the connection weights.
- Lectures: Uninformed Search Algorithms

Queue basics in Python:
# Initializing a queue
queue = []
# Adding elements to the queue
queue.append('a')
queue.append('b')
queue.append('c')
# Print
print(queue)
# Removing elements from the queue
print("\nElements dequeued from queue")
print(queue.pop(0))
print(queue.pop(0))
print(queue)
Representing a graph using dictionary (values are lists of neighbors):
graph = {}
graph['Sibiu'] = ['Fagaras', 'Rimnicu Vilcea']
graph['Fagaras'] = ['Sibiu', 'Bucharest']
graph['Rimnicu Vilcea'] = ['Sibiu', 'Pitesti', 'Craiova']
graph['Pitesti'] = ['Rimnicu Vilcea', 'Craiova', 'Bucharest']
graph['Craiova'] = ['Rimnicu Vilcea', 'Pitesti']
graph['Bucharest'] = ['Fagaras', 'Pitesti', 'Giurgiu']
graph['Giurgiu'] = ['Bucharest']
Shortest path using BFS:
def shortest_path_BFS(graph, start, goal):
To Do:
To Do:
# Call shortest_path_BFS
shortest_path_BFS(graph, 'Sibiu', 'Bucharest')
Expected output:
['Sibiu', 'Fagaras', 'Bucharest']
Chapter 5
1. Alpha-beta pruning
This is not a programming activity, you will solve it in paper (or in computer, if you prefer). For the following game tree show the values of α and β for all the non-leaf nodes (task 1) and show which nodes/sub-tree will be pruned (task 2) by the Alpha-Beta pruning algorithm.
- Lectures: Alpha-beta pruning algorithm

Chapter 22
1. Implement BM25 function
The objective in this activity is to search for ‘relevant’ document/s in a document corpus (database) by implementing the BM25 scoring function. Task: A search query “Word1 Word2” is being scored against 40 documents. The number of times the words “Word1” and “Word2” appear in each of the documents is given in the table. Write a Python program to calculate the BM25 score for the query against all the documents and rank the documents by their BM25 score. You will need to compute IDF, DF, TF, N, L, etc. by reading the table. Assume k = 1.2 and b = 0.75. The code block below suggests the structure for your implementation.
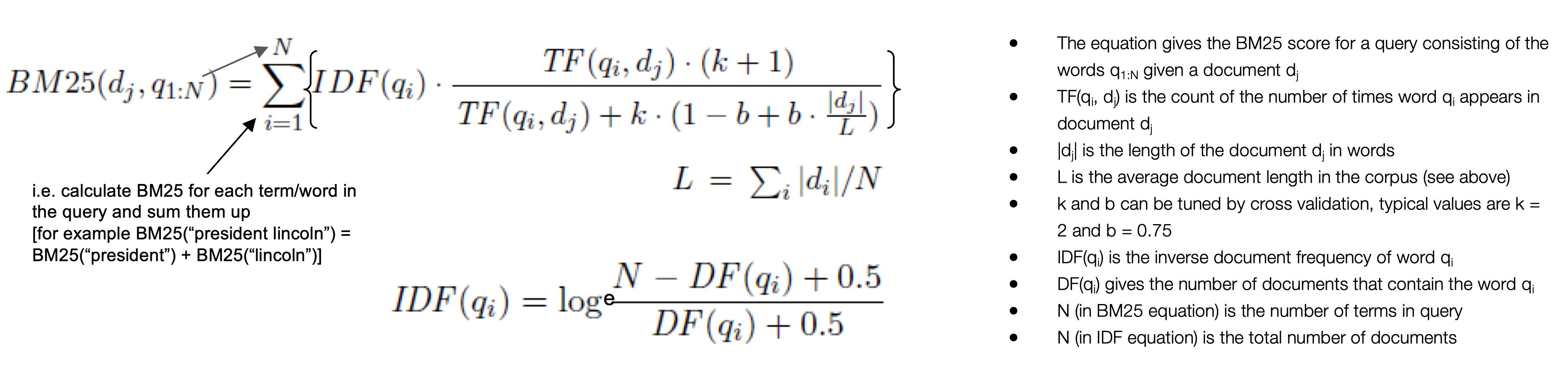{kind=link}
- Lectures: BM25 scoring function
# Step 1: for loops to calculate IDF for Word1 and Word2
...
# Step 2: for loop to calculate L
...
# Step 3: create a dictionary/list to maintain BM25 for each document
bm25 = {}
# Step 4: for loop to calculate BM25 for each document
for each ...:
bm25[doci] = ...
# Step 5: display documents sorted by score
...
2. Implement PageRank algorithm
The objective in this activity is to implement a basic version of the PageRank algorithm - a core algorithm originally developed by Google for ranking pages. Here is the expression for the original version of the PageRank algorithm. Task: For the network shown below, calculate the PageRank of the pages A, B, and C, and D by writing a Python program to iteratively obtain the final page ranks. Assume that the damping parameter d is 0.7. Please follow the solution structure provided in the code block below. Hint: The trick is to count inlinks not outlinks.
{kind=link}
- Lectures: The page-rank algorithm.

Structure for the solution:
# Step1. Initialize the constants N and d
# Step2. Assume that all page ranks are 1.0 at the beginning
prA = 1.0
...
# Step3. In a for/while loop, iteratively update the page ranks of all the pages
for (many times):
prA = "expression for prA"
...
# Step4. Print the page ranks
Chapter 24
1. Implement convolution operation
In this activity you will implement the convolution operation. Your implementation will detect edges in an image. You are required to implement you own convolution function and NOT use existing libraries. Please use the my-cat.csv as your input. Your task is to complete the convolution2D() function in the code below. Hint: You will need to multiply each input pixel (3x3 neighbor grid) of the input 2D array image2D with the input filter kernel3x3 to obtain the output 2D array convolved2D. Note: If you use existing libraries such as scipy.signal.convolve2d you will not receive any points for your submission.
- Articles: First four paragraphs under the section “2D Convolutions: The Operation”
- Lectures: Convolution operation
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
def convolution2D(image2D, kernel3x3):
convolved2D = np.zeros((len(image2D)-2, len(image2D)-2))
# ToDo: Write your code here...
return convolved2D
image2D = np.loadtxt('my-cat.csv', delimiter=',')
sns.heatmap(image2D, cmap='gray')
plt.title('Original image - Size = ' + str(image2D.shape))
plt.show()
edge_detect_filter_3x3 = np.array([[-1, -1, -1], [-1, 8, -1], [-1, -1, -1]])
for i in range(2):
convolved_image = convolution2D(image2D, edge_detect_filter_3x3)
sns.heatmap(convolved_image, cmap='gray')
plt.title('Convolution iteration ' + str(i) + ' - Size = ' + str(convolved_image.shape))
plt.show()
image2D = convolved_image
Expected output:
